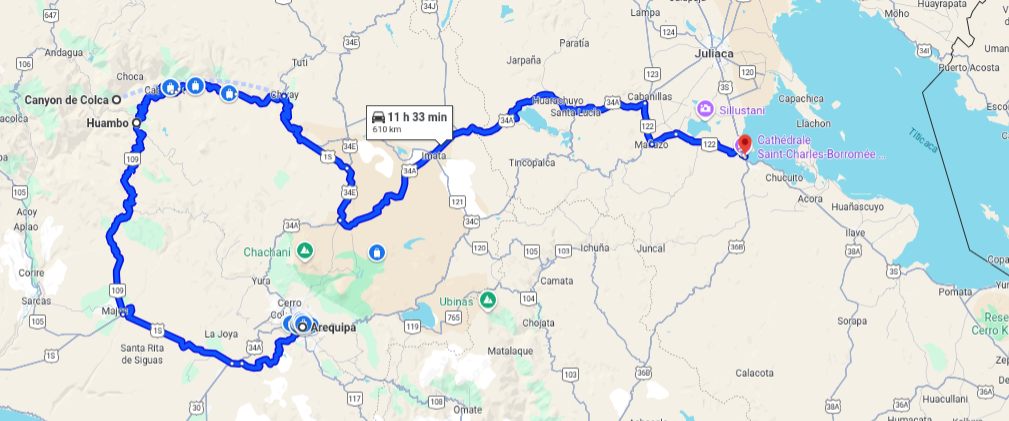
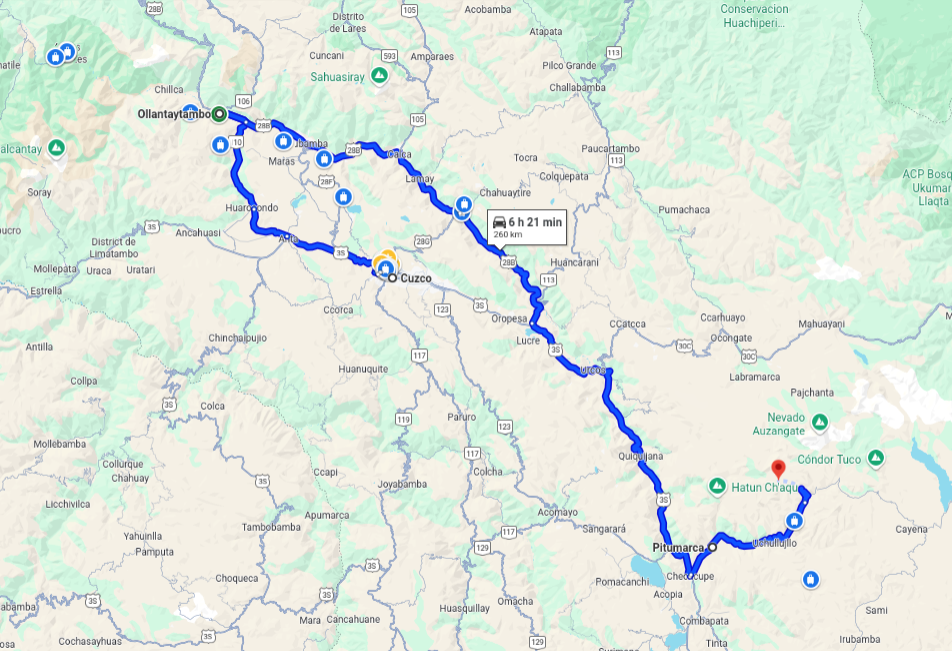
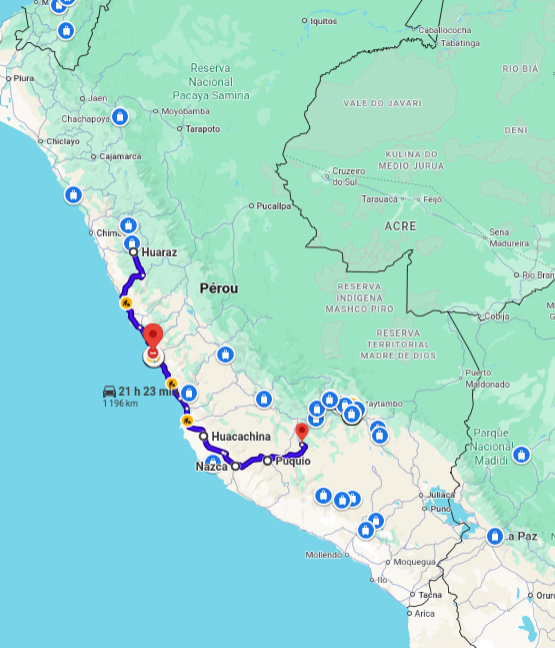
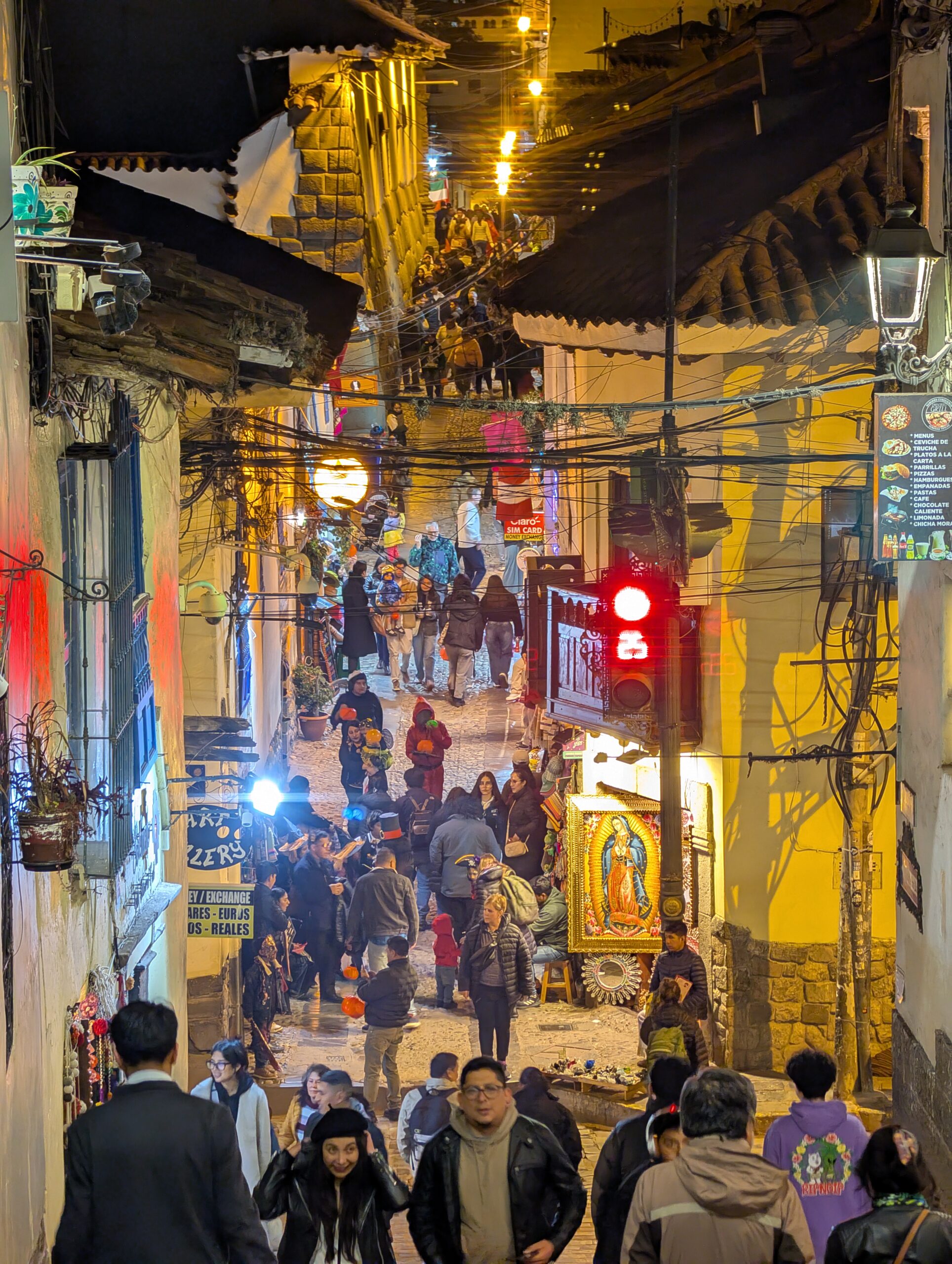Ici, je vous partage nos dernières aventures dans le magnifique pays del Perú. En retard, certes, puisque nous sommes actuellement à Santiago de Chile! Et entre les deux pays nous avons également traversé la Bolivie… puisque nous traversons bientot vers l’Argentine, je vais au moins essayer de conserver un maximum de 2 pays de retard..! L’exercice d’écriture demeure tout de même une portion intéressante du périple car, en plus de tenir au courant ceux qui souhaitaient nous suivre, cela me permet également de me remémorer le périple, et de réfléchir sur ce qui nous a touché.
Arequipa – 5 au 8 novembre
Cette ville, considérée parfois comme la petite sœur de Cuzco pour sa beauté, fut somme toute agréable. À mon sens, c’est surtout une ville facile et confortable, sans peut-être l’éclat ou la fascination que peut dégager sa grande sœur. Une des surprises que j’ai eue fut toutefois le couvent de Santa Catalina. Ayant initialement été ouvert au 16e siècle afin d’accueillir jeunes filles riches et veuves toutes aussi riches, il est le plus grand du monde (2 hectares). Je parle du statut financier de ses premières occupantes, simplement parce que plusieurs d’entre elles achetaient en effet un appartement, pour ainsi dire, dans le couvent. Elles vivaient donc cloîtrées, mais en paix, et certaines possédaient quelques pièces et avaient plusieurs serviteurs à leur service. On dit également que certains événements mondains étaient organisés, divertissant ainsi les résidentes du couvent et leurs invités de marque. Un cloître avec une paroi de dentelle par endroit, donc. Il en résulte une collection de chambres, de cuisines, de petits jardins, de grandes salles, qui vient en fait à en faire un petit village. Le couvent aura toutefois été réformé au 19e siècle, le pape envoyant une religieuse stricte afin de réordonner un peu le quotidien des soeurs. Sa façon de faire parvenir un message que l’on pourrait traduire par “là, ça va faire”. Ainsi, fini les esclaves, le personnel et les festivités. Les sœurs sont restées cloîtrées jusqu’aux années 70 ou 80 du 20e siècle.
En voyage, visiter les lieux de culte est souvent l’un des moments forts, peu importe le pays. Les édifices sont grandioses, l’attention mise à la décoration et aux objets est souvent minutieuse, et le seul fait de s’y retrouver invite au calme et à la méditation. Je me suis donc donné comme objectif de poser le pied dans chaque pièce nous étant accessible, ce que j’ai en effet réussi sans aucun problème. Il faut tout de même garder en tête que l’écrasante majorité du territoire du monastère est seulement utilisé pour les visites du public, les quelques sœurs restantes étant logées dans le seul édifice apparement récent dans l’enceinte. Ce n’est donc pas le présent que l’on visite mais bien le passé, et beaucoup de temps et d’argent ont été mis à la restauration du site. N’empêche, que cela demeure possible en 2025 parle de l’importance historique de l’endroit. Et je l’avoue, j’ai complètement perdu le contrôle sur le nombre de photos…































Canyon de Colca – 8 au 10 novembre
Entre Arequipa et le Lac Titicaca, nous avons repris un peu de hauteur afin d’aller voir, spécifiquement, ce canyon, dont les mérites nous ont été vantés. Déjà la beauté époustouflante apportée par le plus profond canyon au monde (maintenant détrôné par un petit voisin au pays). Et en plus, la chance d’apercevoir des condors. Chance dont nous avons profité, pour le plus grand plaisir de nos yeux. Car oui, bien que ce soit un animal choyé et vénéré des peuples andins, c’est aussi un volatile plus que gracieux, qui glisse sur les courants d’air comme s’il possédait les environs.








Lac Titicaca (ville de Puno) – 10 au 11 novembre
Alors, cette immense étendue d’eau navigable, la plus élevée au monde, nous aura accueillie une soirée. Le lac, en fait, est traversé par la frontière partagée entre le Perú et la Bolivia. Le lac est donc tout aussi partagé… Au premier abord, la ville de Puno est bien classiquement péruvienne: remplie de marchands sur le bord de la rue, dynamique et active. Sinon, l’attrait principal de l’endroit est le lac et ses îles, notamment ses îles flottantes en roseaux. Elles sont une particularité propre à ce lac, et une solution trouvée par la population Uros à l’époque de la colonisation espagnole. Avec ces îles, ils pouvaient tout simplement voguer plus loin avec l’ensemble de leurs possessions pour échapper à l’envahisseur. On dit parfois que la dernière représentante de ce peuple serait décédée dans les années 50, on dit aussi que c’est plutôt une acculturation des Uros par leurs voisins riverains Aymaras… dans tous les cas, certaines traditions demeurent mais d’autres se sont perdues, notamment la langue. De nos jours, beaucoup de gens y vivent encore, mais disons que l’objectif a changé: certaines personnes vont souvent travailler en ville, comme chauffeur de taxi-bateau ou dans les diverses industries, et d’autres restent pour accueillir les touristes. Il y a plusieurs îles distinctes et ont y emmène en rotation les touristes, afin de faire profiter à chacun de cette manne. C’est donc… un peu malaisant comme activité (on ne le dira pas trop fort, mais je n’avais initialement pas vraiment envie de faire la visite…). On nous amène sur une île, où nous serons accueillis par 2-3 personnes ayant couvert leur gaminet aux couleurs de leur équipe de foot favorite par un poncho traditionnel, et ayant ajouté une tuque tressée par dessus leur casquette (je n’exagère même pas). Ils proposent donc des items souvenirs après quelques infos transmises sur la fabrication des îles. Puis on passe à l’autre île, l’île « restaurant », où l’on a finalement pris un thé avant de repartir pour la terre ferme.
C’est le type de situation qui m’amène à réfléchir aux raisons qui font en sorte que je voyage. Qu’est-ce que je je veux voir, ou pas, et qu’elle est ma relation a l’authenticité. Et je pose un regard critique sur ma propre personne mais aussi sur mes comparses voyageurs. La ligne est mince entre vouloir connaître, s’informer, s’éduquer, et occasionner par notre propre tourisme un effet de cirque. Car le choix de conserver un mode de vie ancestral est-il mû par un réel souhait de conservation des traditions, ou par une opportunité commerciale, ou potentiellement un peu des deux..? Dans les faits, il n’y a pas de mauvaise réponse, tous les choix se valent. Mais de mon côté, ai-je appris, où ai-je fermé les yeux avec une petite touche de naïveté et d’hypocrisie? Car j’ai déjà visité des endroits où l’on a reconstitué un ancien village de nouvelle France, par exemple, mais les lignes sont claires: on sait qu’il y a des acteurs, et que l’objectif est pédagogique. En voyageant, parfois, j’ai le sentiment que notre seule présence occasionne une distorsion entre le passé et l’actuel, où la frontière se floue. Parce l’on veut voir ce que l’on pense être « le vrai ». Mais dans les faits, ce que l’on nous montre est parfois le « vrai » d’il y a quelques décennies. Des sentiments parfois difficiles à réconcilier…